2024-12-06 HaiPress
AI 사업화 위한 자회사 설립도

조강원 모레 대표가 서울 서초구 사옥에서 매일경제와 인터뷰하고 있다. 이승환 기자 인공지능(AI) 인프라 솔루션 기업 모레(MOREH)는 자체 개발한 한국어 거대언어모델(LLM) 파운데이션 모델인 ‘Llama-3-Motif-102B’(Motif)를 허깅페이스에 오픈소스로 공개했다고 6일 밝혔다.
모레 측은 “국내 IT업계에서 초대형 모델을 누구나 활용할 수 있도록 소스 코드까지 공개하는 것은 극히 드물다”며 “이번 Motif 사례가 향후 한국 AI 생태계 성장에 기여할 수 있을 것으로 기대된다”고 전했다.
모레에 따르면 Motif는 1020억 개의 매개변수(파라미터)를 가진 한국어 LLM으로,한국판 AI 성능 평가 체계인 ‘KMMLU’ 벤치마크에서 글로벌 빅테크 AI 중 최고 수준으로 평가받는 오픈AI의 GPT-4보다 높은 점수를 받았다. Motif는 64.74점으로 최고 수준의 점수를 기록하며 메타나 구글,네이버의 LLM 보다도 뛰어난 한국어 처리 성능을 입증했다는 게 이 회사 설명이다.
회사 관계자는 “Motif의 뛰어난 성능은 토큰 기준으로 1870억 개에 달하는 방대한 양의 한국어 학습량과 독자적인 학습 기법으로 설명할 수 있다. 웹상에서 수집 가능한 글뿐만 아니라,공개된 전문 분야 문서(국내 특허 및 연구 보고서 등)를 학습 데이터로 활용했다”고 말했다. 이어 “국내 최대 규모의 한국어 정제 데이터를 확보해 학습에 포함시켰다”며 “Motif는 사전 훈련된 언어모델과 지시사항을 따르는 데 특화된 인스트럭트 모델 2가지 버전의 오픈소스가 공개된다”고 덧붙였다.
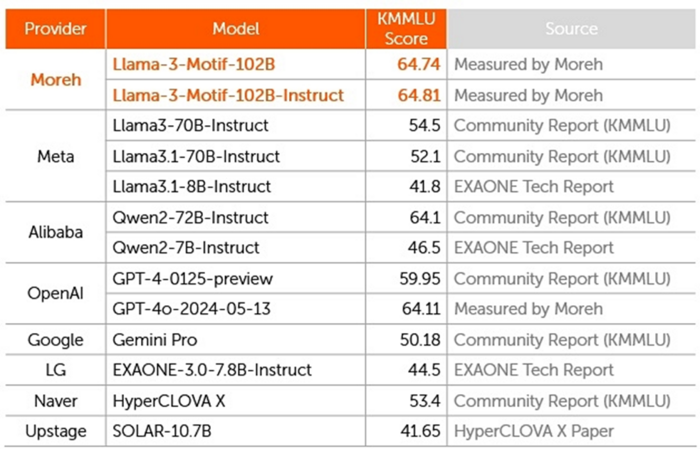
KMMLU 벤치마크 성능 비교표 (2024년 12월 3일 기준) 이에앞서 모레는 이번 한국어 LLM 개발에 앞서 올해 초 영어 LLM도 선보인 바 있다.
700억 개의 매개변수를 가진 거대언어모델인 모레의 ‘MoMo-70B’은 세계 최대 머신러닝 플랫폼 허깅페이스에서 운영하는 ‘오픈 LLM 리더보드’ 평가에서 77.29점이라는 높은 점수를 기록하며 글로벌 1위에 오르기도 했다.
특히 모델 개발 착수에서 1위 달성까지 단 3개월 만에 거둔 성과라고 이 회사는 소개했다. 모레는 이러한 개발 과정에서 얻은 노하우를 바탕으로 더 복잡한 문장을 학습(depth)하고,대화에서 유려한 표현(width)을 만들어내는 Motif를 완성할 수 있었다고 설명했다.
모레가 이처럼 단기간에 영문과 국문 LLM 분야에서 세계 1위 수준의 두각을 나타낼 수 있었던 것은 AI 모델 개발을 위한 최적의 인프라인 AI 플랫폼 기술을 자체 개발해 보유하고 있기 때문이다. 최고 수준의 LLM을 빠르게 개발하기 위해서는 무엇보다 효율적인 모델 학습 방법을 확보하는 것이 중요한데 모레의 ‘MoAI’ 플랫폼은 고도의 병렬화 처리 기법을 통해 대규모 AI 모델을 효율적으로 개발하고 학습할 수 있도록 돕는다.
모레 관계자는 “또한 LLM 개발을 위한 자체 노하우 및 고품질의 한국어 데이터셋 완성,고유의 필터링 기법 등은 모두 국내 최고 수준의 AI 전문 인력이 뒷받침되었기 때문에 가능한 일이었다”고 전했다. 실제로 모레는 순수 국내 기술로 만든 최초의 슈퍼컴퓨터 ‘천둥’ 개발 등 국내에서 슈퍼컴퓨팅 분야를 가장 오래 연구한 서울대 매니코어프로그래밍연구단 출신들이 주축이 돼 창업한 회사다. 2020년 9월 설립된 이래 현재 53명의 석박사급 연구진을 포함해 한국과 베트남에 120여 명의 전문 인력이 함께하고 있다.
조강원 모레 대표는 “독보적인 기술력을 바탕으로 끝없는 실험과 개발 여정을 통해 개발한 고성능 LLM을 누구나 활용할 수 있도록 오픈소스로 공개하는 것은 무엇보다 국내 AI 생태계가 보다 발전적인 방향으로 성장하고 소버린 AI에 기여하기 위함”이라며 “우리와 같은 국내 AI 산업 발전을 위해 노력하는 스타트업 등 많은 기업들이 적극 활용해주면 좋겠다”고 밝혔다.
한편 모레는 AI 모델 사업을 본격 추진하기 위해 별도의 자회사를 설립할 예정이다.
02-26
02-24
02-24
02-24
02-14
02-13
02-11
02-10
02-02
02-02

